If you’re working with Microsoft Fabric and running multiple notebooks to refresh data from different sources, you’ve probably asked yourself: “How do I schedule a notebook in Fabric?” or “Is there a way to automate Fabric notebooks instead of running them manually one by one?”
In this post, I’ll show you exactly how I automated dozens of notebooks in Fabric using a single master notebook and a scheduled pipeline. It runs all notebooks in parallel, logs execution results, and makes my data refresh process hands-free and reliable.
Let’s dive into how I built it.
Why Automate Fabric Notebooks?
When you’re managing a data platform, automation isn’t just a luxury—it’s a necessity.
Here’s why I needed to automate Fabric notebooks:
- Too many notebooks: I had more than 25 notebooks, each responsible for refreshing a different table.
- Manual execution is error-prone: Running them one-by-one introduces human error.
- Scheduling: I needed a way to schedule my data refresh overnight—even if I’m not around.
- Auditing: I wanted to track how many records each notebook loads and when.
The solution? One master notebook to run them all, on a schedule, in parallel.
The Automation Logic Explained
Here’s how the process works:
- I created a notebook called
_Data_Refresh. - This notebook runs other notebooks in parallel using Python’s
ThreadPoolExecutor. - Each notebook returns:
- Number of new records,
- Total record count,
- Execution timestamp.
- These values are logged in a Lakehouse table (
RowCount). - A pipeline in Microsoft Fabric runs
_Data_Refreshon a schedule.
Let’s go through the code.
The Master Notebook
This notebook contains the full automation logic. I called this Notebook _Data_Refresh, so it shows up at the beginning of my Notebooks list:
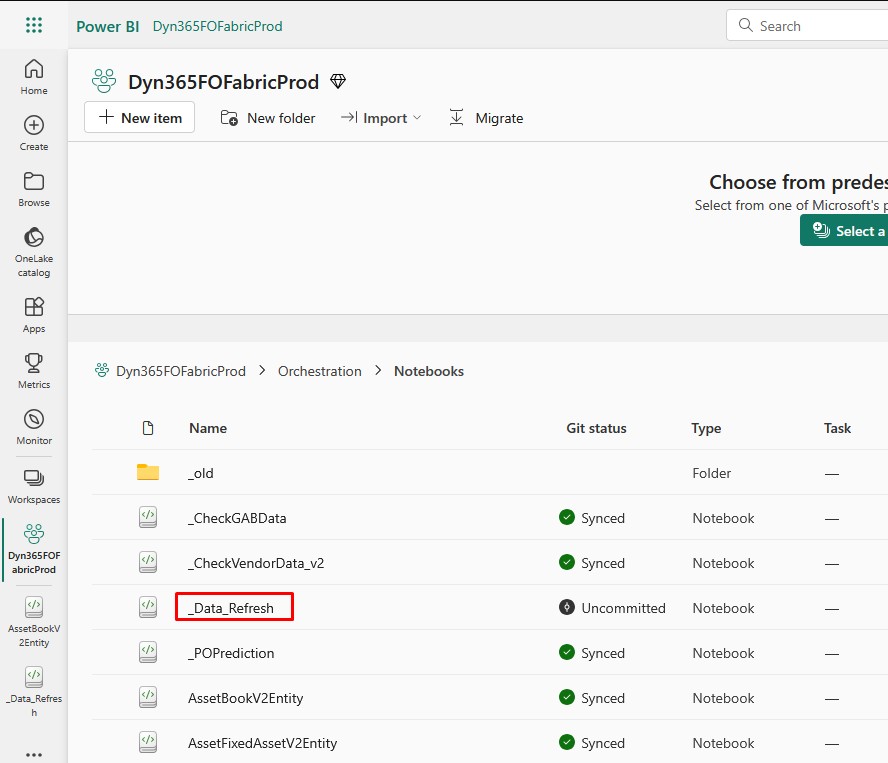
Here is the code for the Notebook:
from notebookutils import mssparkutils
from concurrent.futures import ThreadPoolExecutor, as_completed
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Initialize Spark session
spark = SparkSession.builder.appName("_Data_Refresh").getOrCreate()
# List of notebooks to execute
notebooks = [
"LedgerEntity",
"NumberSequenceEntity",
"DimensionSetEntity",
"FinancialDimensionValueEntity",
"LedgerChartOfAccountsEntity",
"MainAccountEntity",
"DirPartyBaseEntity",
"DirPersonBaseEntity",
"DirPartyEntity",
"LogisticsPostalAddressBaseEntity",
"OMLegalEntity",
"ExchangeRateEntity",
"InventProcurementLedgerPostingDefinitionEntity",
"PurchPurchaseOrderHeaderV2Entity",
"PurchPurchaseOrderLineV2Entity",
"VendVendorV2Entity",
"VendVendorBankAccountEntity",
"VendTransEntity",
"HcmEmployeeV2Entity",
"GeneralJournalAccountEntryReportingEntity",
"EcoResProductV2Entity",
"EcoResReleasedProductV2Entity",
"AssetGroupEntity",
"AssetBookV2Entity",
"AssetFixedAssetV2Entity",
"AssetTransactionListing"
]
# Function to run a single notebook and return the record counts and timestamp
def run_notebook(notebook_name):
try:
# Run the notebook and get the result (expects a string in format "new,total,timestamp")
result = mssparkutils.notebook.run(notebook_name, timeout_seconds=60*60)
new_records, total_records, timestamp = result.split(",") # Split the values
new_records, total_records = int(new_records), int(total_records) # Convert counts to integers
return (notebook_name, new_records, total_records, timestamp)
except Exception as e:
print(f"Notebook {notebook_name} failed: {str(e)}")
return (notebook_name, -1, -1, None) # -1 indicates failure, None for timestamp
# Function to execute multiple notebooks in parallel
def execute_notebooks(notebook_list, max_workers=5):
row_counts = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(run_notebook, nb): nb for nb in notebook_list}
for future in as_completed(futures):
notebook_name, new_records, total_records, timestamp = future.result()
if new_records == -1:
raise Exception(f"Notebook {notebook_name} failed to execute.")
else:
print(f"Notebook {notebook_name} added {new_records} records. Total records: {total_records}. Timestamp: {timestamp}")
# Append the row count data to the list
row_counts.append((notebook_name, new_records, total_records, timestamp))
# After processing all notebooks, write the results to the RowCount table
write_row_counts_to_table(row_counts)
# Function to write row counts to a Microsoft Fabric Lakehouse Table
def write_row_counts_to_table(row_counts):
# Create a DataFrame from the row_counts
row_count_df = spark.createDataFrame(row_counts, ["NotebookName", "NewRecords", "TotalRecords", "ExecutionTimestamp"])
# Perform a merge to ensure only one row per notebook
target_table = "RowCount"
# Use a temporary view for the source DataFrame to allow merging
row_count_df.createOrReplaceTempView("source_row_counts")
# Execute the merge (upsert) operation
merge_query = f"""
MERGE INTO {target_table} AS target
USING source_row_counts AS source
ON target.NotebookName = source.NotebookName
WHEN MATCHED THEN
UPDATE SET
target.NewRecords = source.NewRecords,
target.TotalRecords = source.TotalRecords,
target.ExecutionTimestamp = source.ExecutionTimestamp
WHEN NOT MATCHED THEN
INSERT (NotebookName, NewRecords, TotalRecords, ExecutionTimestamp)
VALUES (source.NotebookName, source.NewRecords, source.TotalRecords, source.ExecutionTimestamp)
"""
# Run the merge query
spark.sql(merge_query)
# Execute the notebooks
try:
execute_notebooks(notebooks)
except Exception as e:
print(f"Error executing notebooks: {str(e)}")
raise
This code is used to automate the execution of multiple Microsoft Fabric notebooks from a single master notebook called _Data_Refresh. It runs all listed notebooks in parallel using Python’s ThreadPoolExecutor, significantly speeding up the data refresh process. Each notebook returns the number of new and total records loaded along with a timestamp. These results are then saved to a RowCount table in the Lakehouse for tracking and audit purposes. The master notebook itself can be scheduled using a Fabric pipeline, enabling fully automated and hands-free data processing.
Fabric Notebook Automation
If you want to schedule fabric notebook, you can do this by creating a pipeline that runs this notebook. Go to Microsoft Fabric and create a new pipeline:
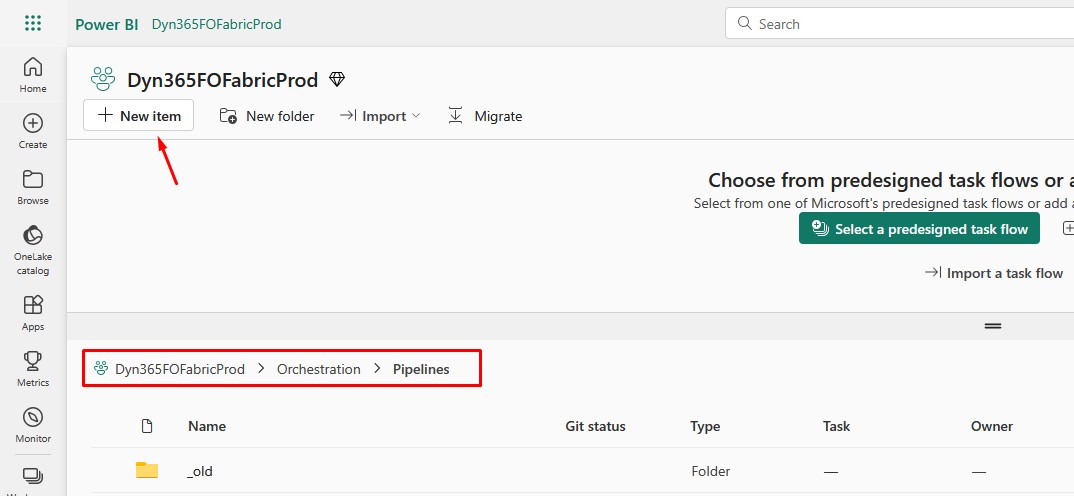
Notice how I use a separate folder where I store my pipelines.
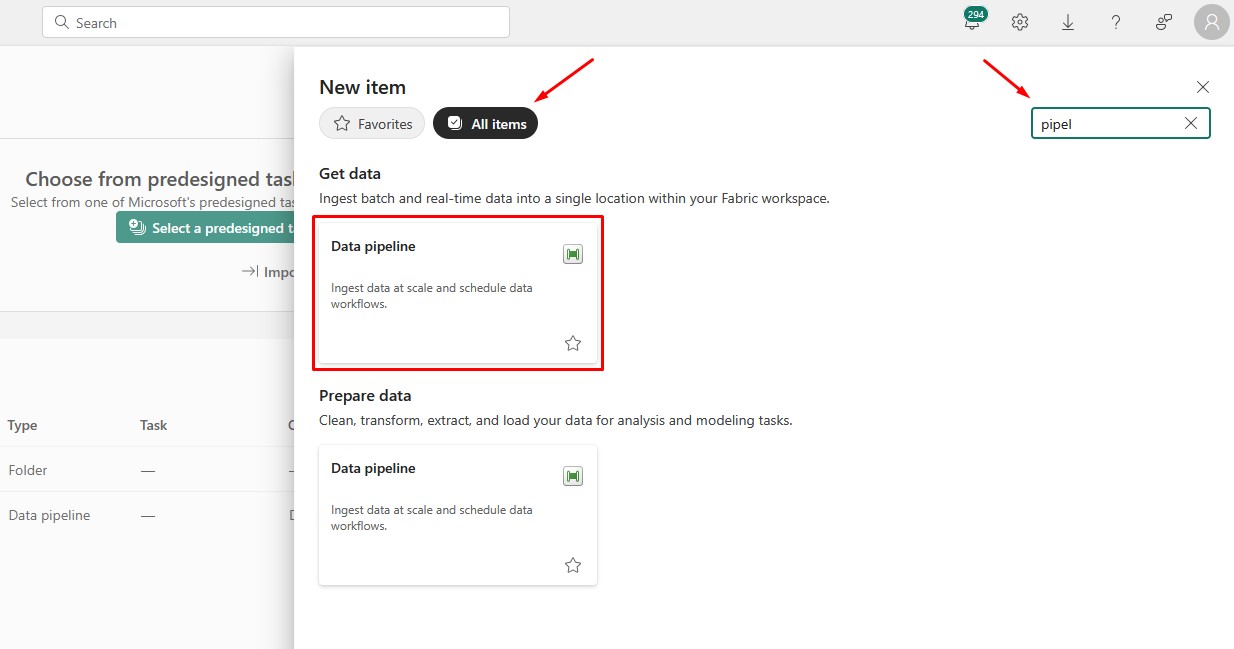
Add a Notebook activity and give it some meaningful name:
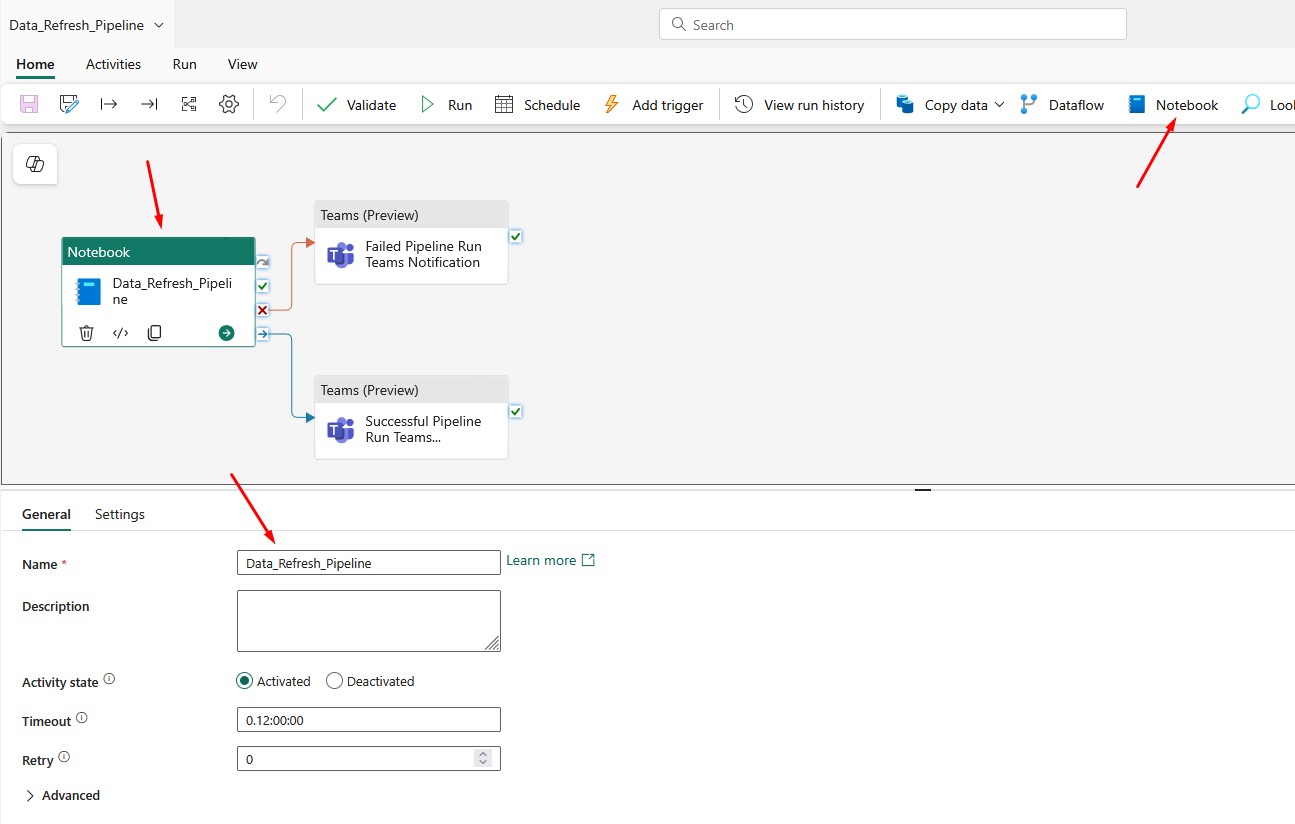
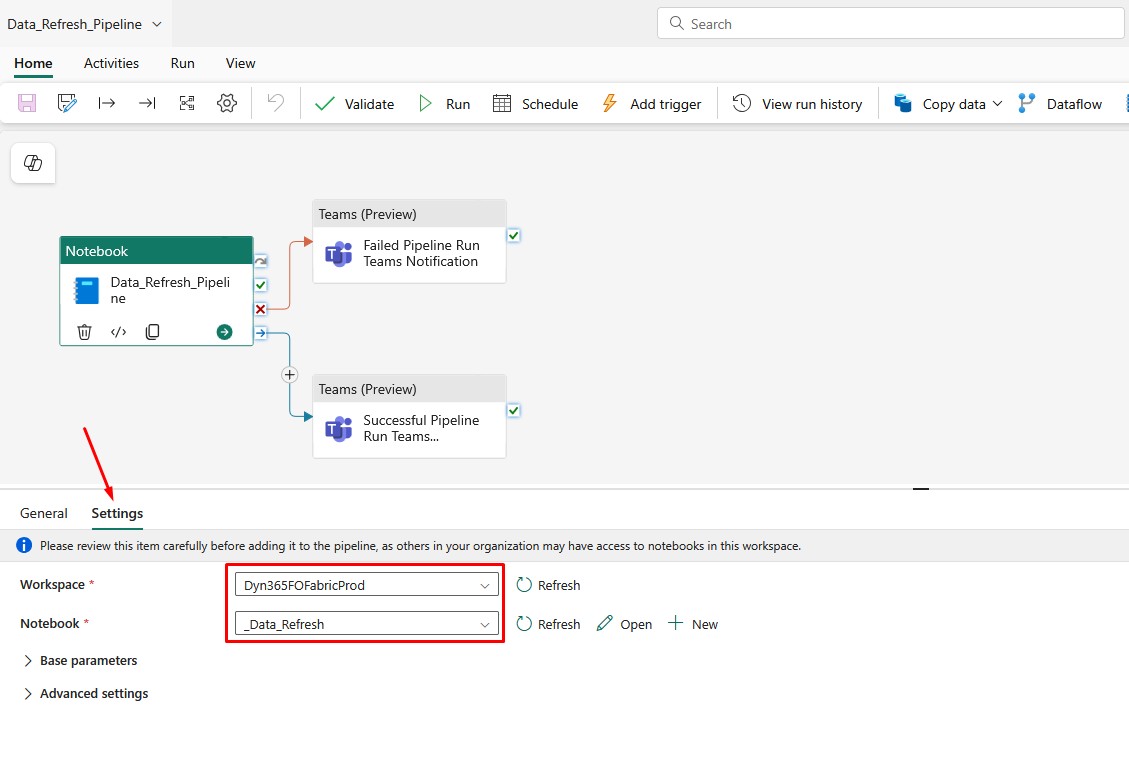
Go to Settings and choose the Workspace and Notebook that runs all the other Notebooks:
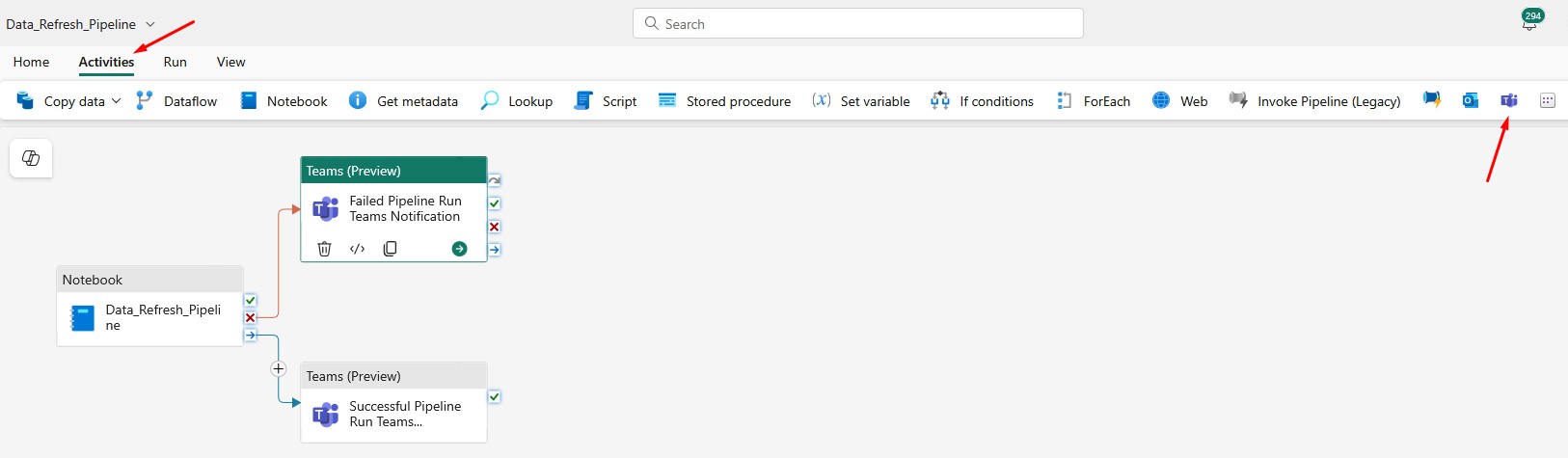
What I usually want is to receive a notification on Teams if the pipeline finished successfully or if it failed:
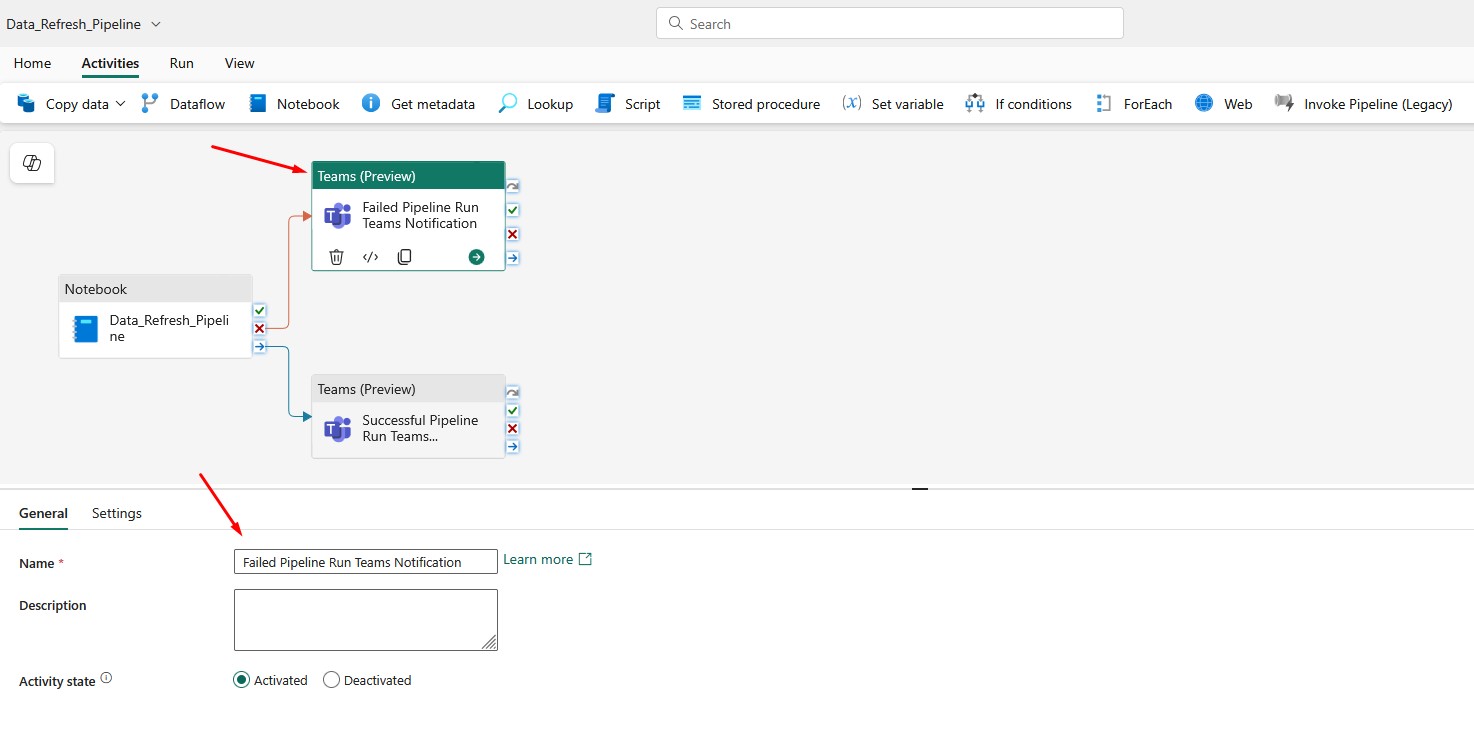
Choose a meaningful name for the Teams activity:
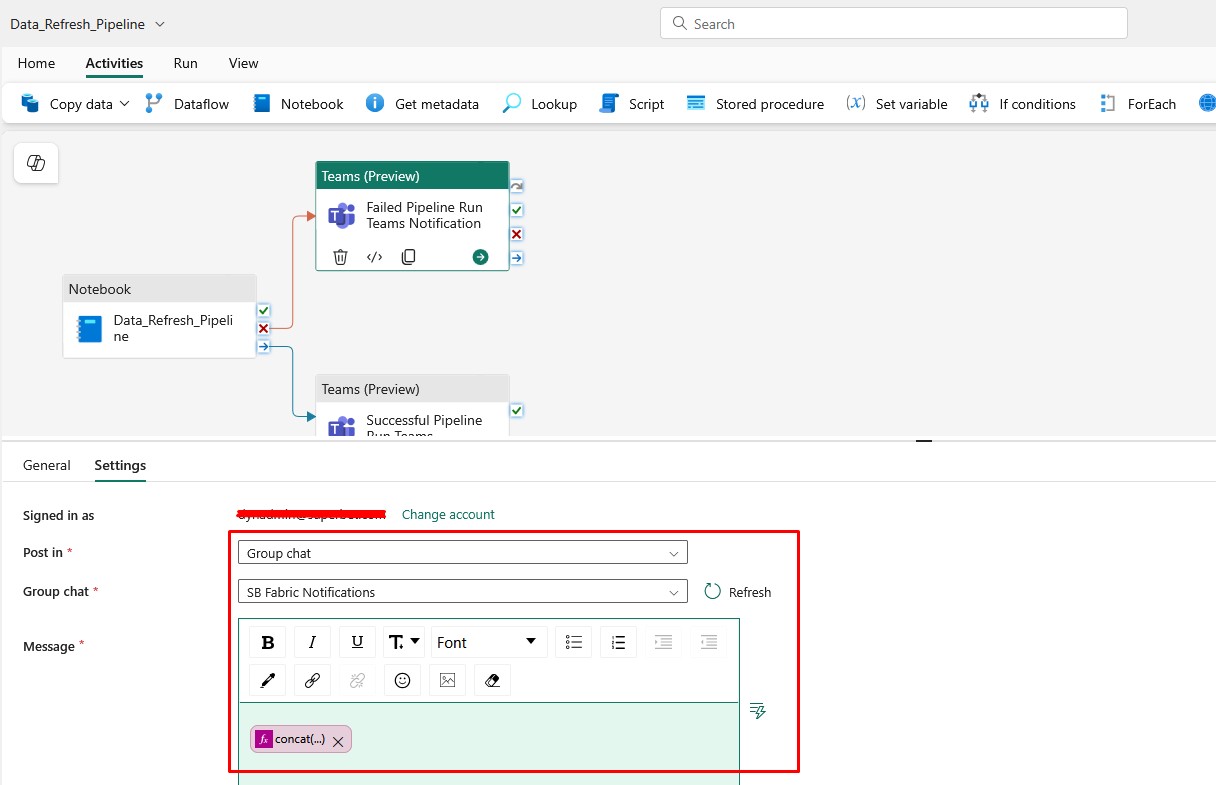
Go to settings, log in with some admin account and select where do you want to receive teams notifications:
I use the following expression as a Message:
<p>@{concat('RunID: ', string(pipeline().RunId), '; YourCompanyName ', pipeline().PipelineName, ' run has failed. ', 'Please check the pipeline run details in Fabric for more information. ', 'Pipeline Run Date: ', utcNow())}</p>
You can add it here:
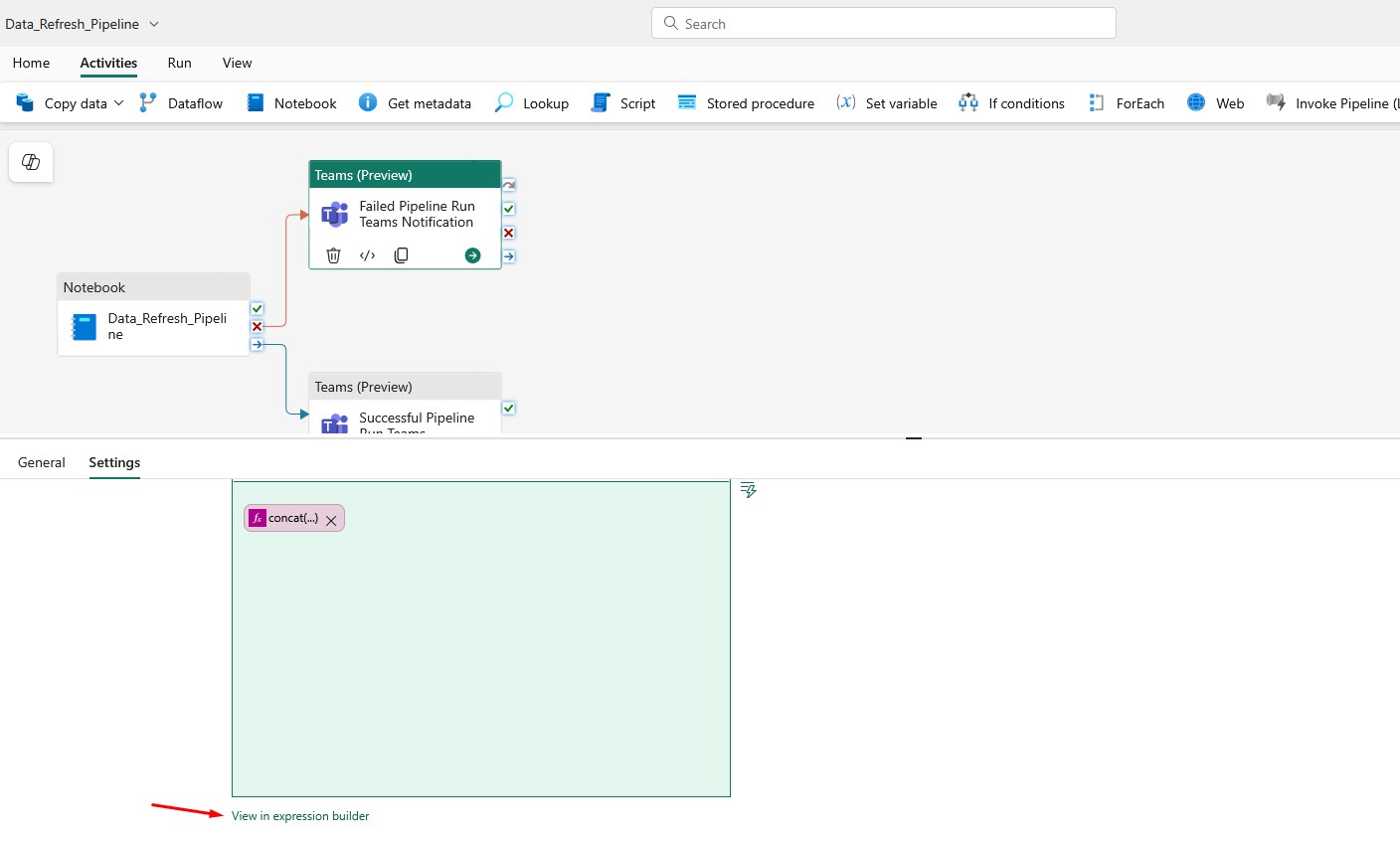
Here’s the expression I use for successful run of the Pipeline:
<p>@{concat('RunID: ', string(pipeline().RunId), '; YourCompanyName ', pipeline().PipelineName, ' run was successful. ', 'Please check the pipeline run details in Fabric for more information. ', 'Pipeline Run Date: ', utcNow())}</p>
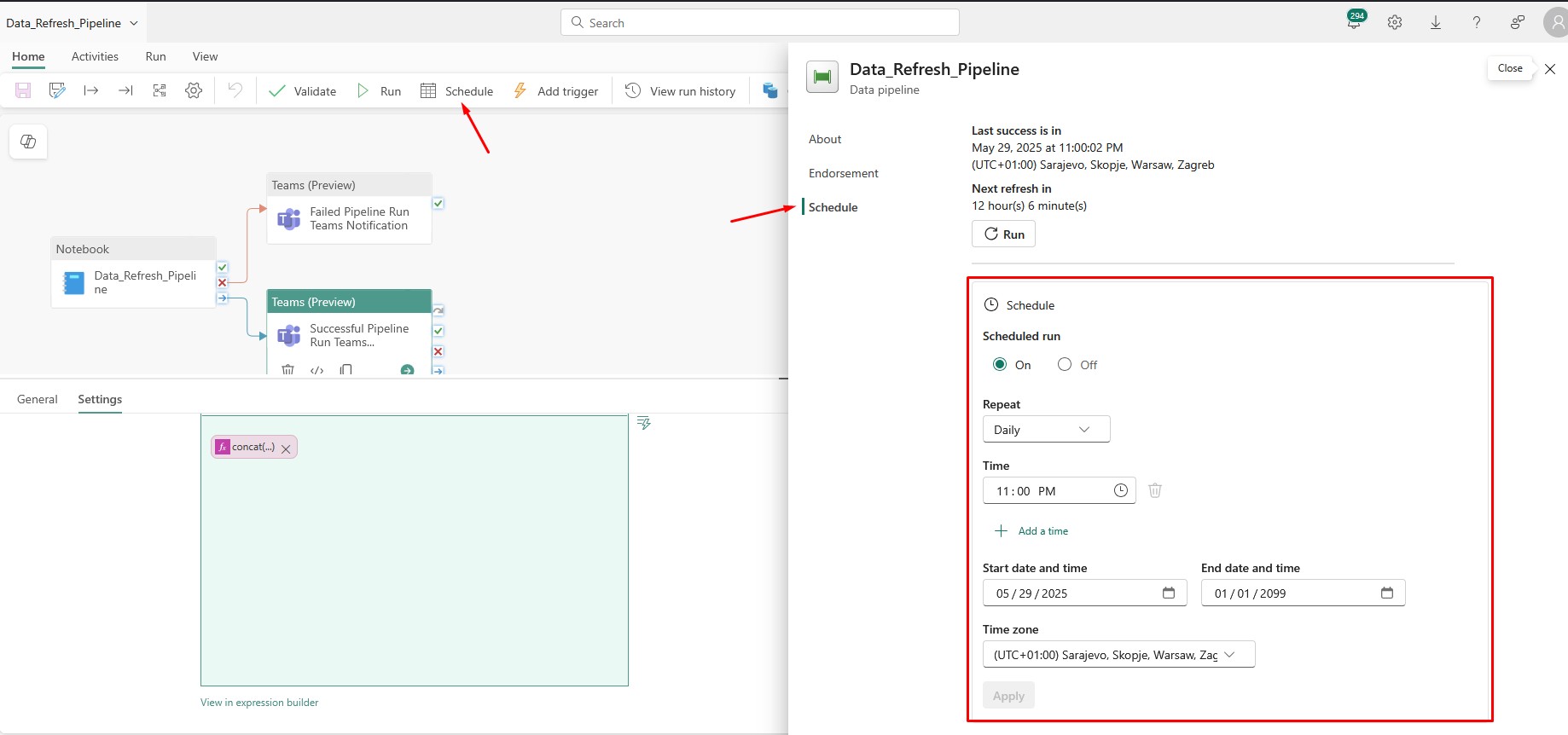
Schedule Fabric Pipeline
I hope the following picture explains how do I schedule a Fabric Pipeline:
RowCount Table for Tracking
I use the RowCount table in my Lakehouse to track:
- What was executed
- When it ran
- How many records were added
This is the code I put at the end of each Notebook that I run with my main _Data_Refresh Notebook:
# Save the result as a Delta table
result_df.write.format("delta").mode("overwrite").saveAsTable("AssetBookV2Entity")
print("The query result has been successfully saved as a table 'AssetBookV2Entity'.")
# Return row count
# Define your table name
table_name = "assetbookv2entity"
# Count the new records added in this execution
new_records_count = result_df.count()
# Get the total number of records in the table after insertion
total_records_count = spark.sql(f"SELECT COUNT(*) FROM {table_name}").collect()[0][0]
# Step 5: Optionally get the current timestamp for the execution
execution_timestamp = spark.sql("SELECT current_timestamp()").collect()[0][0]
# Return new and total records as a string for the main notebook
mssparkutils.notebook.exit(f"{new_records_count},{total_records_count},{execution_timestamp}")
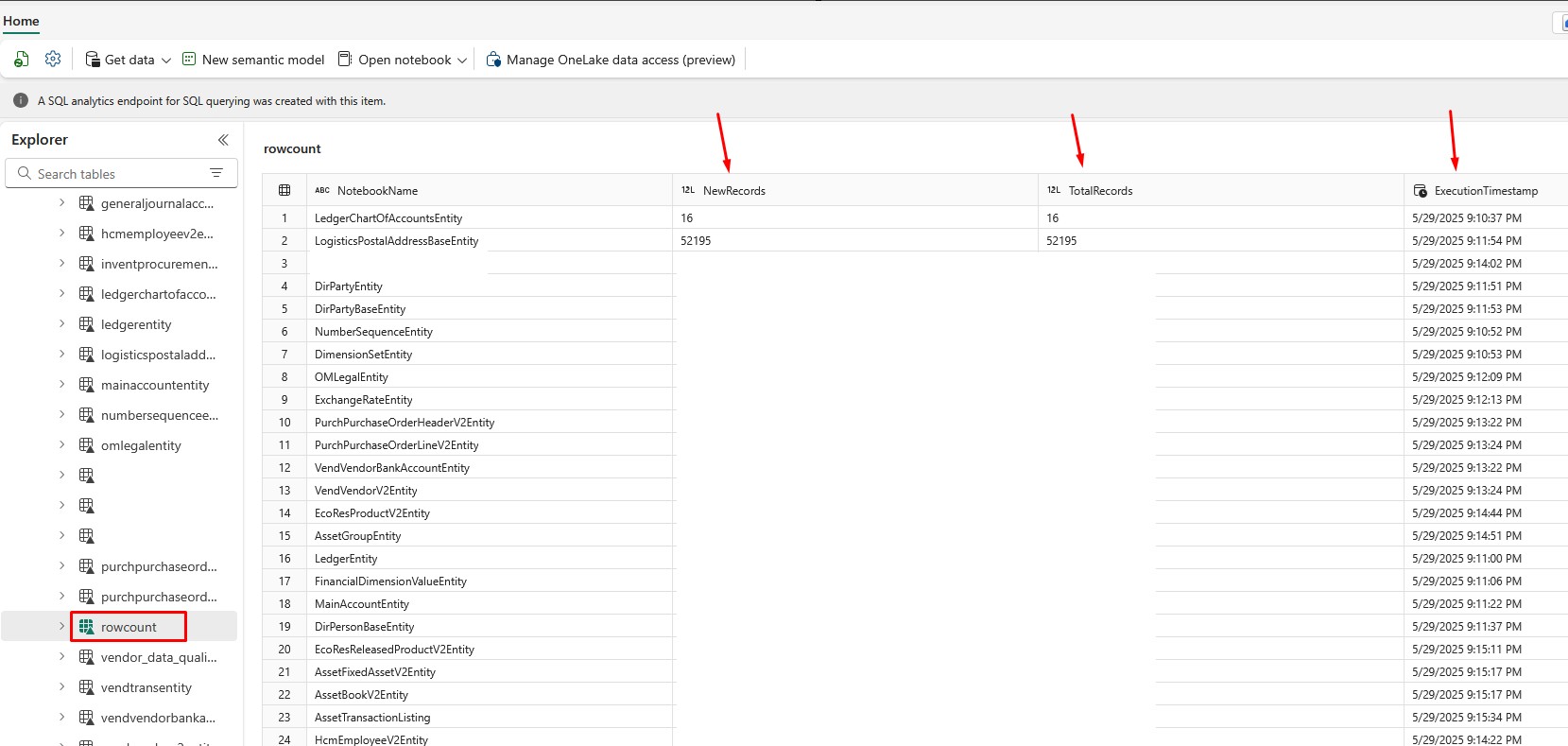
This code saves the data frame as a Lakehouse table, and returns the new records count, total records count and execution stamp. As a result, I get the following table that shows how many new records were added to all my tables and how many total records do I have in each Fabric table. It also shows when was the table updated last time:
Final Thoughts
If you’re looking to automate Fabric notebooks, this setup works beautifully:
- Parallel execution = speed
- Scheduling with pipelines = hands-free automation
- Logging to Lakehouse = visibility and audit trail
You can always improve the setup with better error handling, retries, or separating failed runs for analysis.
Let me know if you try this approach or need help adapting it to your environment!
If you want to learn how to move Fabric items from one Workspace to another, make sure you check my previous blog post here. If you want to learn about Microsoft Fabric for free, you can do that with official training from Microsoft.
There is also a great book on Amazon called Learn Microsoft Fabric: A practical guide to performing data analytics in the era of artificial intelligence that covers some interesting topics.