When you work long enough with business data, you eventually run into one of the biggest headaches in data management – duplicates. Levenshtein distance calculation is one of the ways to solve this issue.
I recently had to help our team that maintains the Vendor Master catalog in D365F&O. We kept noticing that some vendors were listed twice — sometimes even three times — but with small variations in the name or tax ID. For example:
- “Contoso Ltd” and “Contoso Ldt”
- “Northwind Traders” and “Northwind Trader”
- “DE123456789” and “de123456789”
All of these look like the same vendor, but for a computer, they’re different strings. That’s when I decided to use Levenshtein distance calculation inside Microsoft Fabric to help us automatically identify such cases.
Why Data Quality Matters
Data quality isn’t just a “nice to have.” Poor-quality data silently destroys trust in reports, processes, and decision-making. In our case, duplicate vendor records meant duplicated transactions, wrong approvals, and extra manual work.
Most ERP systems, including D365F&O, won’t automatically tell you that two vendors are suspiciously similar. So, you need to build a data check layer on top of your source — and that’s where Microsoft Fabric and PySpark become extremely powerful.
What Is Levenshtein Distance?
The Levenshtein distance is a simple but brilliant concept. It measures how many single-character edits (insertions, deletions, or substitutions) you’d need to transform one word into another.
For example:
Levenshtein("cat", "cut") = 1Levenshtein("kitten", "sitting") = 3
So if two words differ by only one or two characters, they’re probably the same entity with a typo.
When you apply this idea to vendor names or tax IDs, it becomes a great way to spot duplicates that are almost identical.
Levenshtein Distance Calculation in Microsoft Fabric
Here’s how I implemented it in PySpark within a Microsoft Fabric notebook to detect similar vendor names and tax IDs.
Our Vendor Master data comes from the vendvendorv2entity table, which is automatically synchronized from D365F&O to our Lakehouse.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, expr
from pyspark.sql import functions as F
spark = SparkSession.builder.appName("CheckVendorData").getOrCreate()
# Load Vendor Master Data
df = spark.read.format("delta").load("Tables/vendvendorv2entity")
# Normalize key fields
df = df.withColumn("name_norm", F.lower(F.trim(col("vendororganizationname")))) \
.withColumn("taxid_norm", F.lower(F.trim(col("taxexemptnumber"))))
# Repartition by legal entity for performance
df = df.repartition(4, "dataareaid")
This part loads the vendor data, cleans up spaces and casing (so “Contoso Ltd” and “contoso ltd” are treated equally), and improves performance by grouping by dataareaid.
Detecting Similar Vendor Names
Then, I used a self-join to compare every vendor with every other vendor in the same legal entity and calculate the Levenshtein distance between their names:
similar_names_df = df.alias("a").join(
df.alias("b"),
(col("a.dataareaid") == col("b.dataareaid")) &
(col("a.vendoraccountnumber") != col("b.vendoraccountnumber")) &
(col("a.name_norm").isNotNull()) &
(col("b.name_norm").isNotNull())
).withColumn("levenshtein_distance", expr("levenshtein(a.name_norm, b.name_norm)")) \
.withColumn("length_ratio", expr("length(a.name_norm) * 1.0 / length(b.name_norm)")) \
.filter((col("levenshtein_distance") <= 1) & (col("length_ratio") >= 0.95) & (col("length_ratio") <= 1.05)) \
.select(
col("a.dataareaid"),
col("a.vendoraccountnumber"),
col("a.vendororganizationname"),
col("a.taxexemptnumber"),
col("b.vendoraccountnumber").alias("related_vendoraccountnumber"),
lit("Similar Vendor Name").alias("issue_type")
)
Here’s what’s happening:
- It compares vendors only within the same legal entity.
- It skips identical account numbers (so a vendor isn’t compared to itself).
- The
levenshtein()function computes how similar the names are. - The
length_ratiocheck ensures we don’t compare names of completely different lengths. - Finally, it keeps only the pairs where the distance is small, meaning the names are almost identical.
Here is what it looks like in Microsoft Fabric Notebook:
Detecting Similar Tax IDs
The same logic applies to Tax IDs. Sometimes a user forgets a digit or types it in a different format.
similar_tax_df = df.alias("a").join(
df.alias("b"),
(col("a.dataareaid") == col("b.dataareaid")) &
(col("a.vendoraccountnumber") != col("b.vendoraccountnumber")) &
(col("a.taxid_norm").isNotNull()) &
(col("b.taxid_norm").isNotNull())
).withColumn("levenshtein_distance", expr("levenshtein(a.taxid_norm, b.taxid_norm)")) \
.withColumn("length_ratio", expr("length(a.taxid_norm) * 1.0 / length(b.taxid_norm)")) \
.filter((col("levenshtein_distance") <= 1) & (col("length_ratio") >= 0.95) & (col("length_ratio") <= 1.05)) \
.select(
col("a.dataareaid"),
col("a.vendoraccountnumber"),
col("a.vendororganizationname"),
col("a.taxexemptnumber"),
col("b.vendoraccountnumber").alias("related_vendoraccountnumber"),
lit("Similar Tax ID").alias("issue_type")
)
Combining and Saving the Results
Once both checks are done, I combined them and saved the results to a Delta table:
issues_df = similar_names_df.union(similar_tax_df)
issues_df.write.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.save("Tables/vendor_data_quality_issues")
print("Vendor data quality check complete. Issues saved to: Tables/vendor_data_quality_issues")
Now we have a clean Delta table (vendor_data_quality_issues) listing all potential duplicates, ready to be exported or reviewed in Power BI for further cleanup. Each record in the table will clearly indicate what kind of issue does this vendor potentially have:
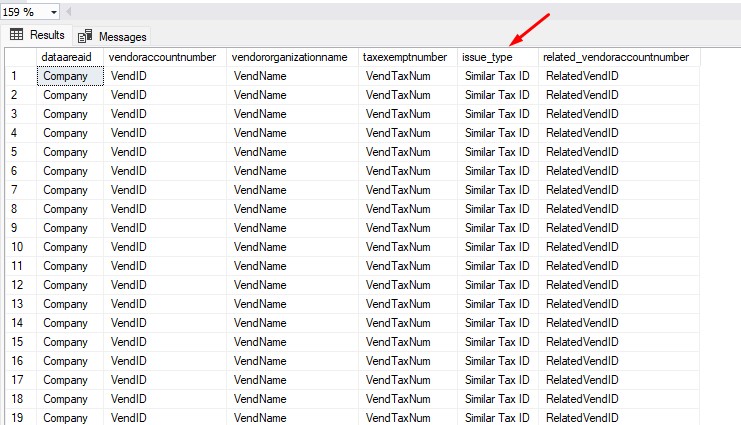
Lessons Learned
Using Levenshtein distance in Microsoft Fabric turned out to be a simple yet powerful way to improve our data quality.
Here’s what I took away from this task:
- Even small typos can cause big problems in ERP data.
- Normalizing text before comparison is crucial.
- PySpark’s
levenshtein()function is surprisingly efficient when combined with repartitioning. - Building this in Microsoft Fabric made it easy to automate and integrate into our existing data pipelines
Final Thoughts
Data quality isn’t just about enforcing strict validation rules. It’s about continuously finding and fixing small inconsistencies that sneak into your data over time. The Levenshtein distance calculation is a great example of how a simple string metric can uncover hidden issues and make your data more reliable.
In our case, this approach helped us clean up hundreds of duplicate vendor records and build trust in our Vendor Master catalog again.
If you’re working with D365F&O or any other ERP system and suspect you have duplicates hiding in your data, try applying the Levenshtein distance calculation in Microsoft Fabric. You might be surprised by what you find.
If you want to learn more about Microsoft Fabric , make sure you check my last blog post on How to Truncate Tables in Microsoft Fabric. There is also a great book on Amazon called Learn Microsoft Fabric: A practical guide to performing data analytics in the era of artificial intelligence that covers some interesting topics.