In this post, I’ll show you how to truncate tables in Microsoft Fabric in three different ways: directly in the Lakehouse, in the Warehouse, and by automating the process with a Pipeline.
If you’re working with Microsoft Fabric, you’ll eventually face a situation where you need to clear out all data from a table but keep its structure. That’s when truncating comes in handy. Unlike dropping a table, truncation removes all rows but preserves the schema, columns, and metadata.
How to Truncate Tables in Microsoft Fabric Lakehouse?
In the Lakehouse, tables are stored as Delta tables. Delta doesn’t support the traditional TRUNCATE TABLE command, but you can still achieve the same result.
The recommended approach is to overwrite the table with an empty DataFrame using PySpark. The following PySpark code deletes the table that we created in one of my previous blog posts on How to Import Excel into Fabric.
NOTE: When creating a Notebook, don’t forget to add a data item (your lakehouse):
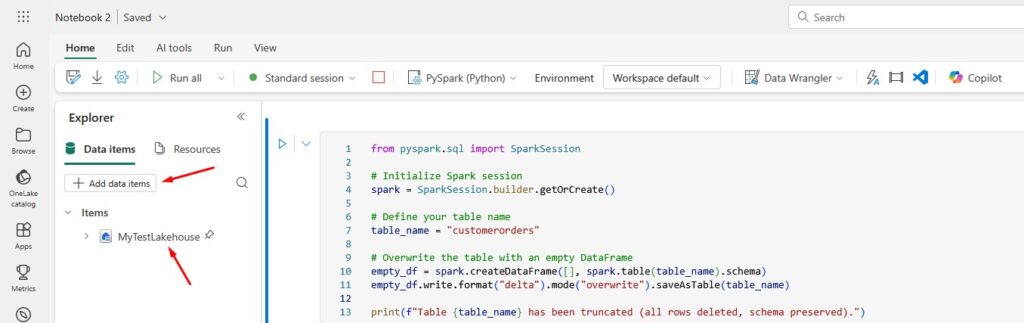
Now, here is the PySpark code:
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.getOrCreate()
# Define your table name
table_name = "customerorders"
# Overwrite the table with an empty DataFrame
empty_df = spark.createDataFrame([], spark.table(table_name).schema)
empty_df.write.format("delta").mode("overwrite").saveAsTable(table_name)
print(f"Table {table_name} has been truncated (all rows deleted, schema preserved).")
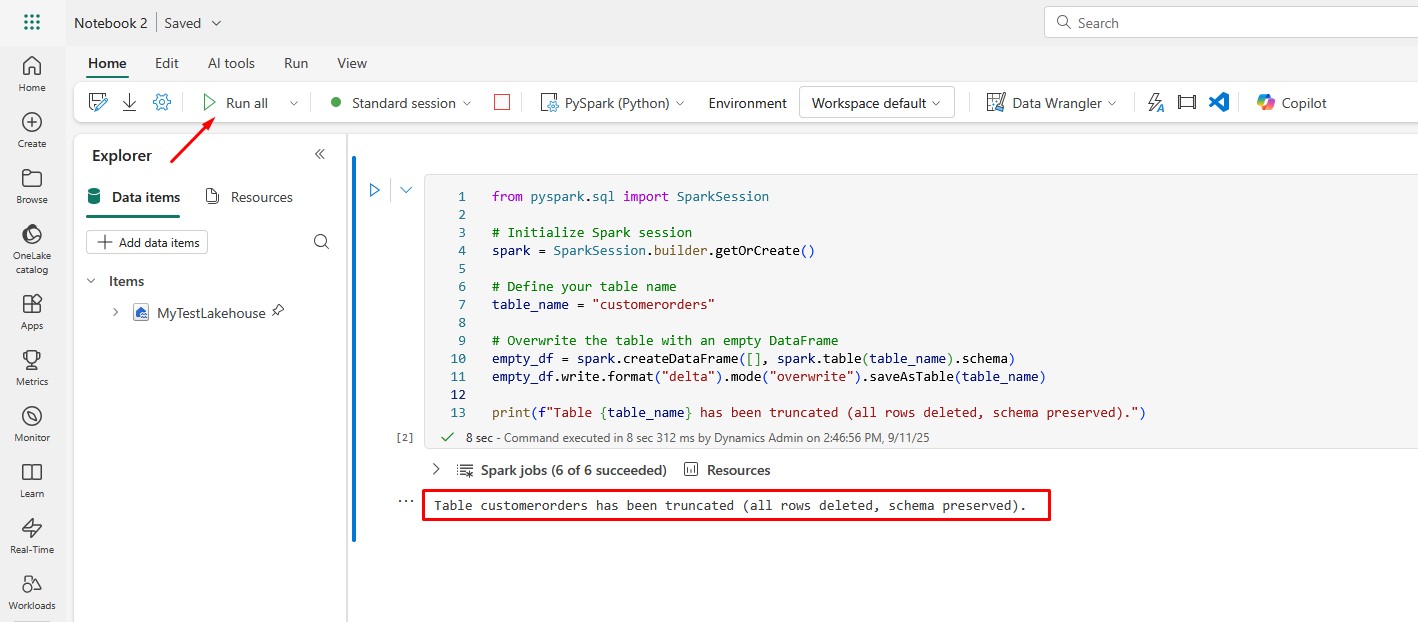
Run the Notebook and you will see the message below:
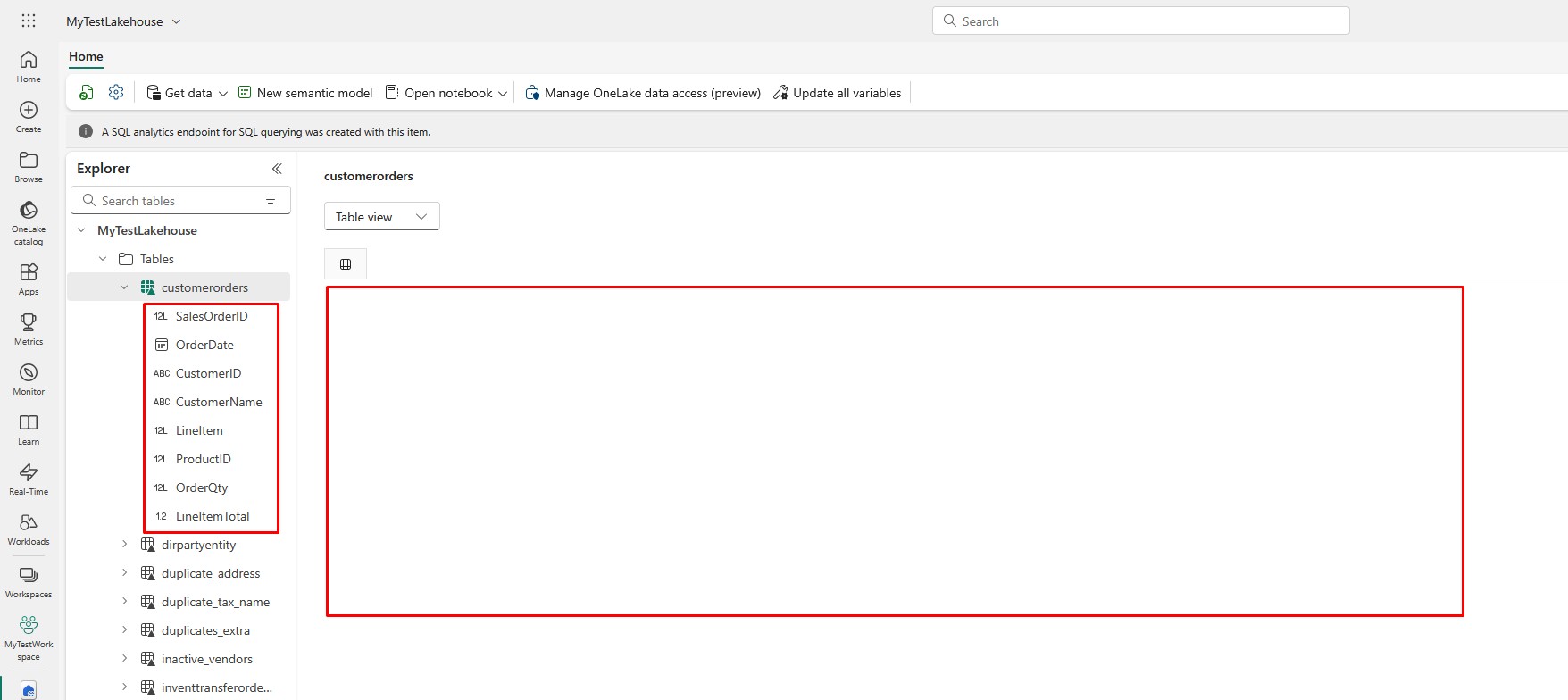
If you check the table, you will see that it does not contain any data, but it keeps the schema:
How to Truncate Tables in Microsoft Fabric Data Warehouse?
Fabric Warehouses are SQL-based, and here you can use the traditional T-SQL command:
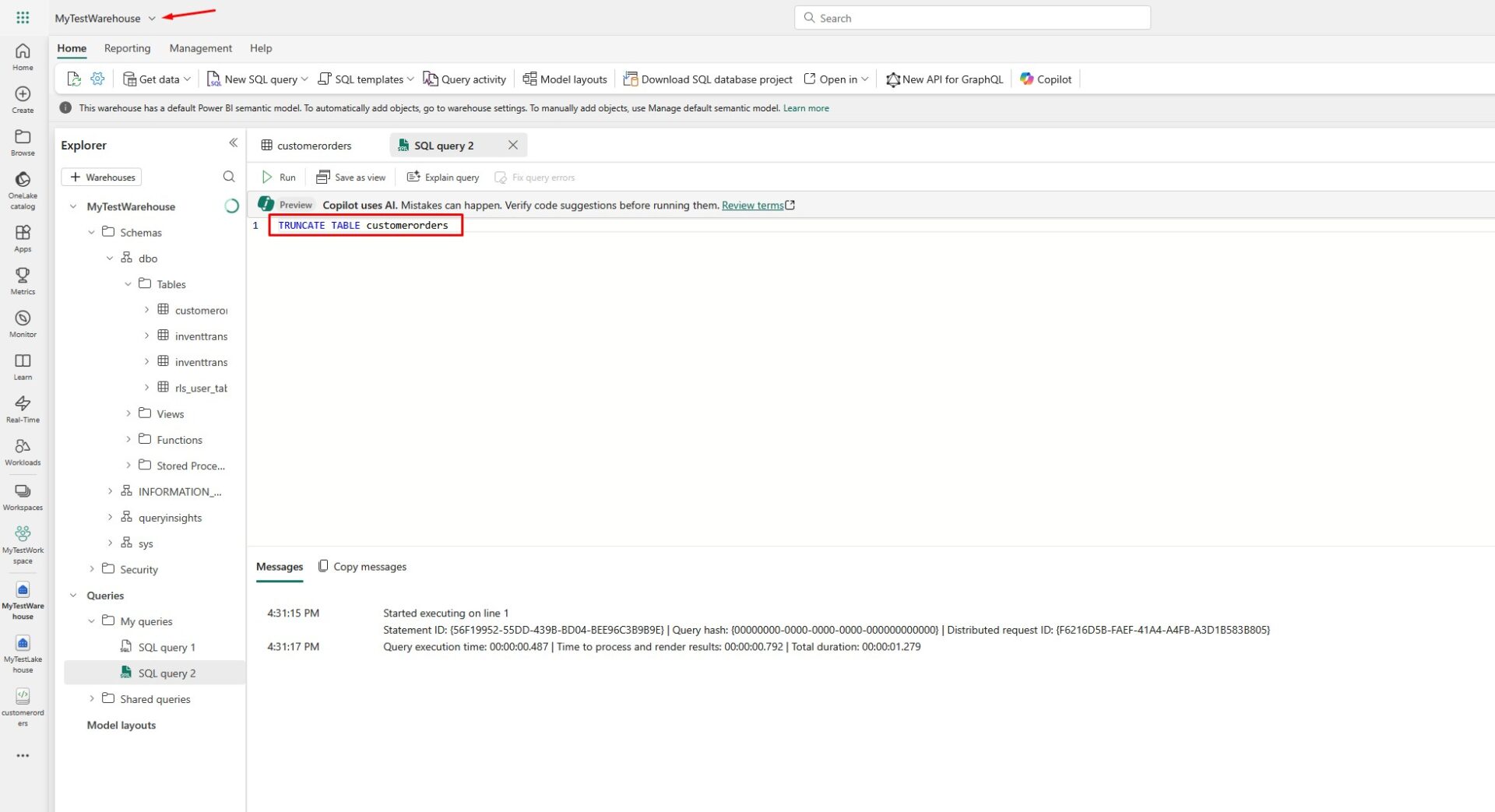
TRUNCATE TABLE customerorders
Here is what it looks like in Fabric:
This is the fastest way to truncate tables in Microsoft Fabric Warehouse. It doesn’t log individual row deletions, making it much more efficient than using DELETE.
How to Truncate Tables in Microsoft Fabric with a Pipeline
If you want to automate truncation before reloading staging tables during ETL, you can do this with a Fabric Data Pipeline.
Steps:
- Create a new Pipeline in your Fabric workspace.
- Add a Notebook activity (for Lakehouse tables) or a SQL script activity (for Warehouse tables).
- Paste the PySpark or SQL truncate code.
- Add a Schedule Trigger so the truncation runs before data refresh.
Here is an example of a stored procedure that truncates tables in my data warehouse before I load the data:
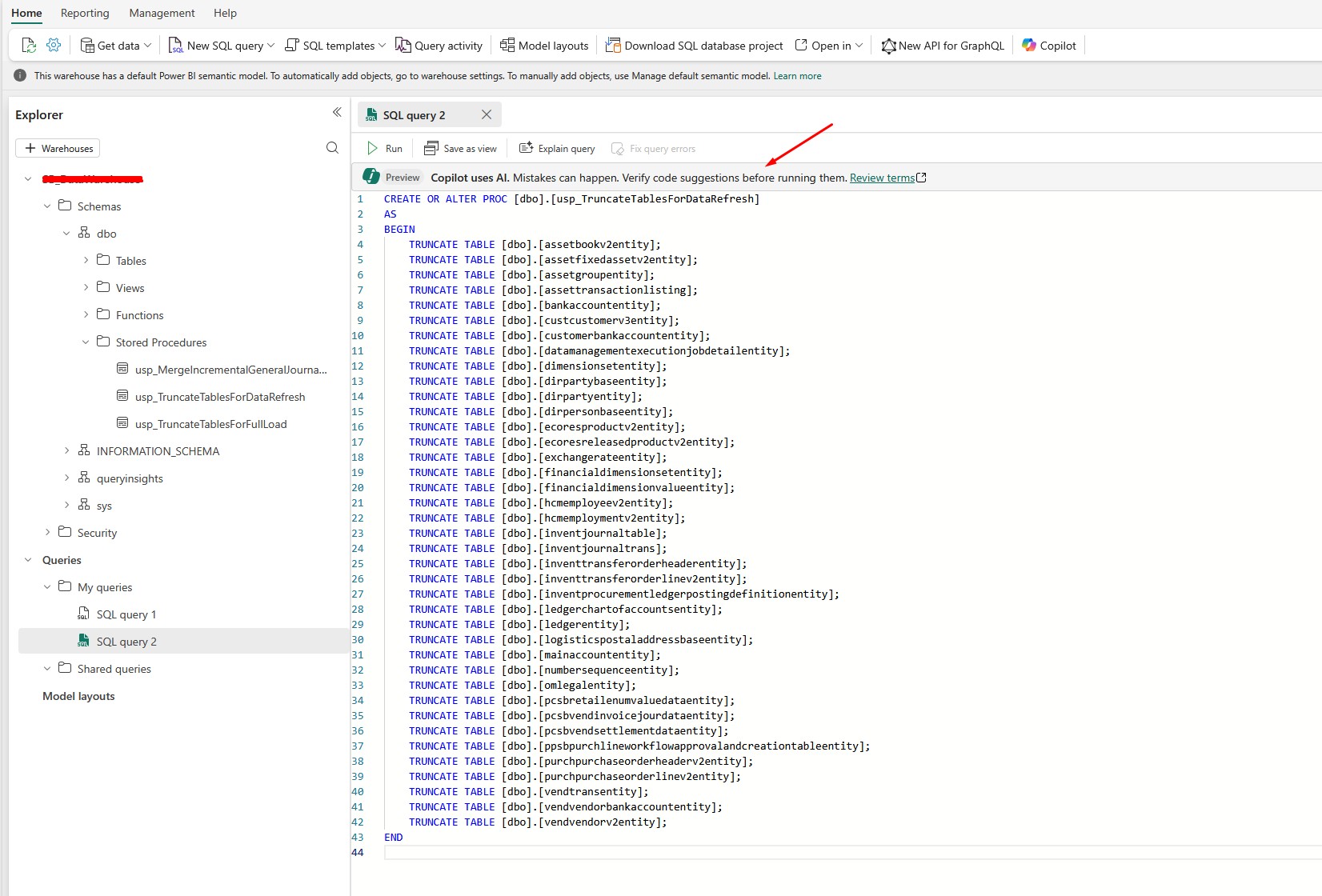
After that, I call the stored procedure in a pipeline:
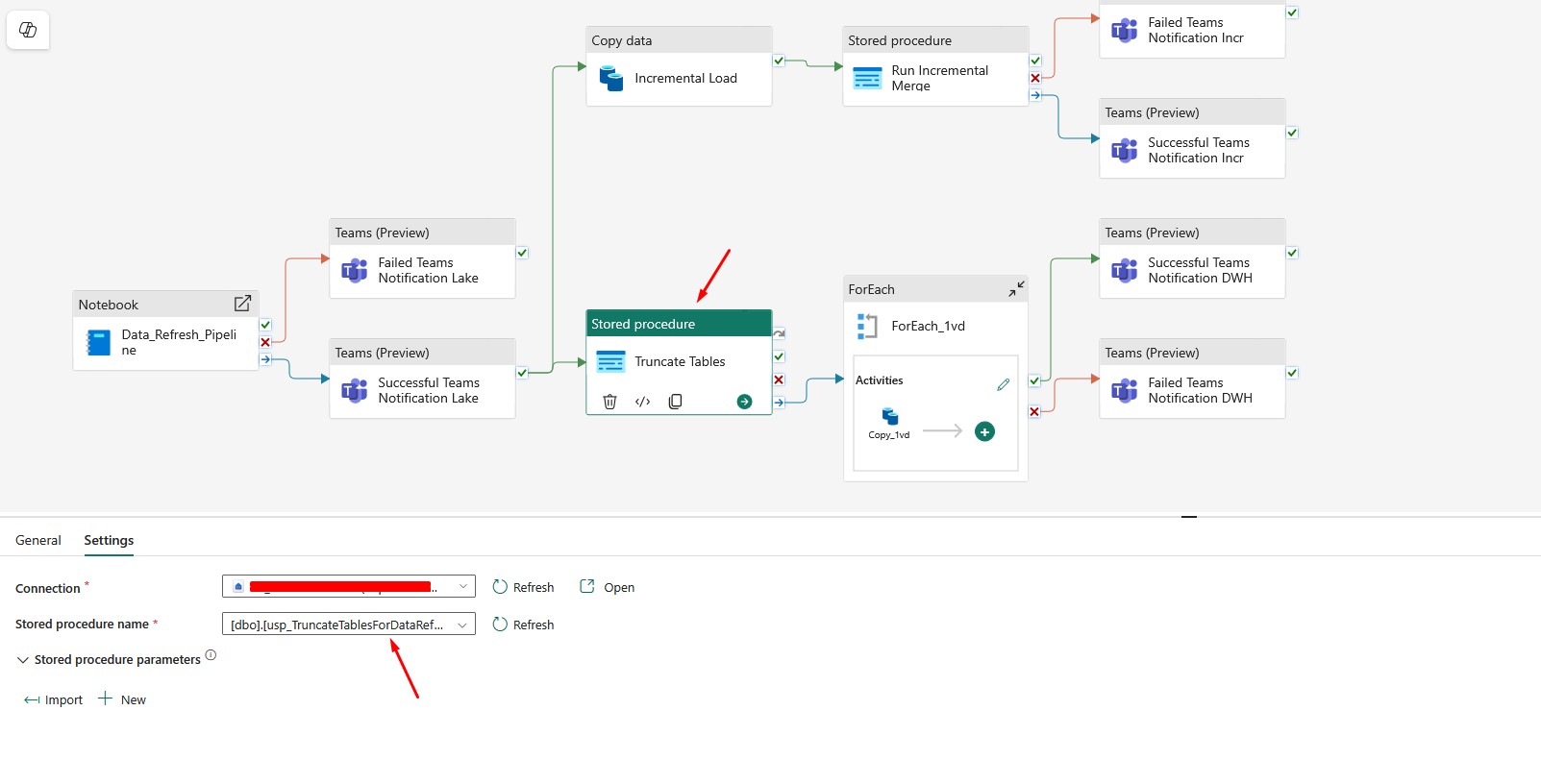
Important Warning Before Truncating Tables
Truncating is irreversible. Once you truncate a table, all data is gone instantly, and there’s no way to roll it back.
Best practices before truncating tables in Microsoft Fabric:
- Never truncate production tables unless you’re absolutely sure.
- Only truncate staging or temporary tables used in ETL/ELT processes.
- If you must truncate important tables, take a backup or snapshot first.
Final Thoughts
Knowing how to truncate tables in Microsoft Fabric gives you flexibility in managing your data pipelines.
- In the Lakehouse, overwrite with an empty DataFrame for efficiency.
- In the Warehouse, use
TRUNCATE TABLEfor fast cleanup. - With Pipelines, automate truncation before new data loads.
Use the right approach for your scenario, and always be cautious when working in production environments.
If you want to learn more about Microsoft Fabric , make sure you check my last blog post on How to Import Excel into Fabric. There is also a great book on Amazon called Learn Microsoft Fabric: A practical guide to performing data analytics in the era of artificial intelligence that covers some interesting topics.